Using Byteman to locate deadlock-prone data source access patterns on WebSphere
The other day I came across a very interesting deadlock situation in an application deployed on a production WebSphere server. The deadlock occurred because for certain requests, the application requires more than one concurrent connection from the same JDBC data source in a single thread. This situation arises e.g. when an application uses transaction suspension (e.g. by calling an EJB method declared with REQUIRES_NEW) and the new transaction uses a data source that has already been accessed in the suspended transaction. In that case, the container is required to retrieve a new connection from the pool, resulting in two connections from the same data source being held by the same thread at the same time. Since the size of the connection pool is bounded, this may indeed lead to a deadlock if multiple such requests are processed concurrently. There is very well written explanation of that problem in the WebSphere documentation:
Deadlock can occur if the application requires more than one concurrent connection per thread, and the database connection pool is not large enough for the number of threads. Suppose each of the application threads requires two concurrent database connections and the number of threads is equal to the maximum connection pool size. Deadlock can occur when both of the following conditions are true:
Each thread has its first database connection, and all are in use.
Each thread is waiting for a second database connection, and none would become available since all threads are blocked.
To prevent the deadlock in this case, increase the maximum connections value for the database connection pool by at least one. This ensures that at least one of the waiting threads obtains a second database connection and avoids a deadlock scenario.
For general prevention of connection deadlock, code your applications to use only one connection per thread. If you code the application to require C concurrent database connections per thread, the connection pool must support at least the following number of connections, where T is the maximum number of threads:
T * (C - 1) + 1
The deadlock situation can be visualized using a resource allocation diagram. With 4 threads, a maximum connection pool size of 4 and C=2, the diagram would look as follows:
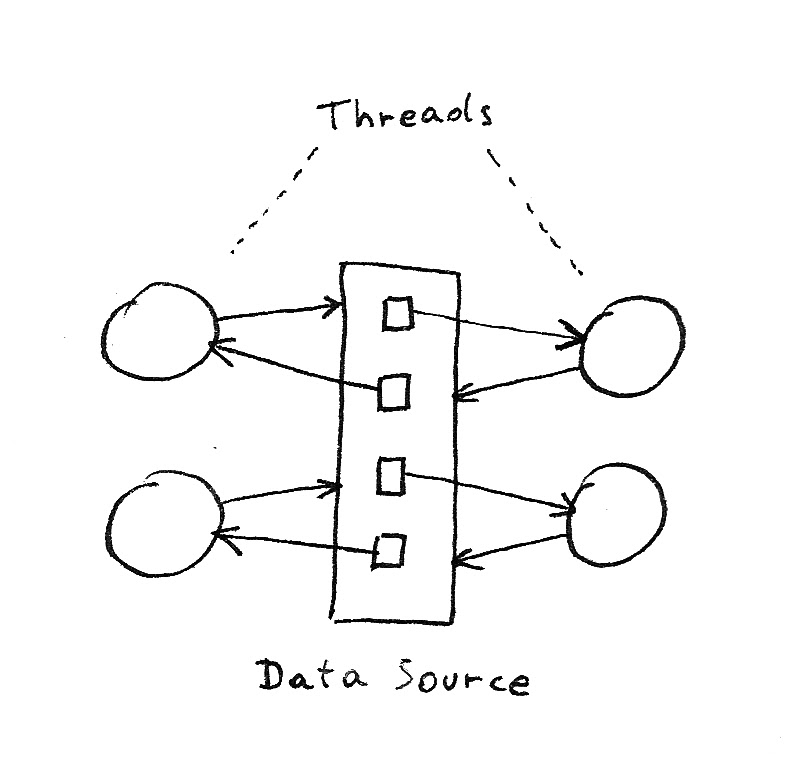
Note that since blocked connection requests eventually time out (by default after 3 minutes), the situation is not a real (permanent) deadlock. However, after a given thread is unblocked by a timeout (and the connection held by that thread released), the system will typically reach another deadlock state very quickly because of application requests that have been queued in the meantime (by the Web container if requests come in via HTTP).
What makes this problem so nasty is that it is a threshold phenomenon. Under increasing load the system will at first behave gently: as long as the maximum pool size is not reached, it is not possible for the deadlock to occur and the system will respond in a normal way. If the load increases further, the number of active connections will eventually reach the limit and the probability for the deadlock to occur will become non zero. Once the deadlock materializes, the behavior of the system drastically changes, and the impact is not limited to requests that require multiple concurrent connections per thread: any request depending on the data source (even with C=1) will be blocked. This will rapidly lead to a thread pool starvation, blocking all incoming requests, even ones that don’t use the data source. As noted above, connection request timeouts will not necessarily improve the situation, even if the load (in terms of number of incoming requests per unit of time) decreases below the level that initially triggered the deadlock.
To illustrate the last point, assume that the normal response time of the service is of order 100ms and that the maximum connection pool size is 10. In this scenario the threshold above which the deadlock may occur is of order 100 req/s. Once the deadlock occurs, the average response time drastically changes. It will be determined by the connection request timeout configured on the data source, which is 3 minutes by default. The actual average response time will be lower because once a timeout occurs and a connection becomes available in the pool, a certain number of requests may go through without triggering the deadlock again. Let’s be optimistic and assume that in that state the average response time will be of order 10 seconds. Then the new threshold will be of order 1 req/s, i.e. for the deadlock to clear there would have to be a drastic decrease in load.
As noted in the WebSphere documentation quoted above, there are two options to avoid the problem. One is to set the maximum pool size for the data source to a sufficiently high value. Note that as long as there are requests with C>1, the maximum connection pool size must be larger than the thread pool size. There are some problems with this option:
-
In many environments there is a limit on the total number of open connections allowed by the database. Configuring large connection pools may cause a problem at that level.
-
Increasing connection pool sizes also increases the maximum number of SQL statements that may be executed concurrently. This may cause problems for the database server in other scenarios.
The other option is to review the application and to make sure that C≤1 for all requests. This raises another interesting question, namely how to identify code for which C>1 without the need to carry out specific load tests that attempt to trigger the actual deadlock or to implement costly code reviews (that would probably miss some scenarios anyway). Ideally one would like to identify such code by simply monitoring the application in a test environment. In principle this should be feasible because the algorithm to detect this at runtime is trivial: if a thread requests a new connection from a pool while it already owns one, take a stack trace and log the event.
It appears that WebSphere Application Server doesn’t have any feature that would allow to do that. On the other hand this is a typical use case for tools such as BTrace. Unfortunately BTrace is known not to work on IBM JREs because it uses an undocumented feature that only exists in Oracle JREs. There is however a similar tool called Byteman that works on IBM JREs.
The following Byteman script indeed achieves the goal (Note that it was written for WAS 8.5; it may need some changes to work on earlier versions):
HELPER helper.Helper
RULE connection reservation
CLASS com.ibm.ejs.j2c.PoolManager
METHOD reserve(javax.resource.spi.ManagedConnectionFactory, javax.security.auth.Subject, javax.resource.spi.ConnectionRequestInfo, java.lang.Object, boolean, boolean, int, int, boolean)
AT EXIT
IF true
DO reserved($0, $!)
ENDRULE
RULE connection release
CLASS com.ibm.ejs.j2c.PoolManager
METHOD release(com.ibm.ws.j2c.MCWrapper, java.lang.Object)
IF true
DO released($0, $1)
ENDRULE
The script simply intercepts the relevant calls to the connection pool manager that are used for reserving and releasing connections.
It then extracts the MCWrapper object (MC stands for managed connection; there is one wrapper for each physical connection in
the pool) and passes it to a helper class that takes care of the bookkeeping. If the helper detects that two wrappers from
the same pool are used by a single thread, it will log that event. The class looks as follows:
package helper;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
public class Helper {
// Note: key is PoolManager and values are MCWrapper. We need to use Object because the helper is
// added to the classpath of the server. If we want to use the actual classes, then we would have
// to load the helper as a fragment into the com.ibm.ws.runtime bundle.
private static final ThreadLocal<Map<Object,Set<Object>>> threadLocal
= new ThreadLocal<Map<Object,Set<Object>>>() {
@Override
protected Map<Object,Set<Object>> initialValue() {
return new HashMap<Object,Set<Object>>();
}
};
public void reserved(Object poolManager, Object mcWrapper) {
Map<Object,Set<Object>> map = threadLocal.get();
Set<Object> mcWrappers = map.get(poolManager);
if (mcWrappers == null) {
mcWrappers = new HashSet<Object>();
map.put(poolManager, mcWrappers);
}
// Note that the same MCWrapper may be returned twice if the connection is sharable and requested
// multiple times in the same transaction (which is OK); however we don't need to track that
// because "released" is only called once per MCWrapper.
mcWrappers.add(mcWrapper);
if (mcWrappers.size() > 1) {
System.out.println("Detected concurrent connection requests for the same pool in the same thread!");
System.out.println(poolManager);
new Throwable().printStackTrace(System.out);
}
}
public void released(Object poolManager, Object mcWrapper) {
// Note that this method is called only once per MCWrapper for shared connections (i.e. when
// the MCWrapper is really put back into the pool).
threadLocal.get().get(poolManager).remove(mcWrapper);
}
}
That class needs to be added to the class path of the server. The Byteman script itself is enabled by adding the following argument to the JVM command line of the WebSphere server:
-javaagent:/path_to_byteman/lib/byteman.jar=script:/path_to_script/websphere.btm
When the detection mechanism is triggered, it will output a dump of the connection pool as well as a stack trace for the code that requests the concurrent connection. The connection pool dump will show at least one connection with a managed connection wrapped linked to a transaction in state SUSPENDED. It is easy to improve the helper class to collect the stack trace for the first connection request as well. Note however that this changes requires the helper to save a stack trace for every connection request (even for code with C=1) which would have an impact on performance.